11 C Peru Gap#
Steady state implementation#
Preamble#
We are going to run this notebook in parallel using ipyparallel. To do this we launch a parallel engine with nprocs processes. Following this, all cells we wish to run in parallel need to start with the jupyter magic %%px.
%%px
Cells without the %%px magic will run locally and will not have access to anything loaded on the parallel engine.
import ipyparallel as ipp
nprocs = 2
rc = ipp.Cluster(engine_launcher_class="mpi", n=nprocs).start_and_connect_sync()
Starting 2 engines with <class 'ipyparallel.cluster.launcher.MPIEngineSetLauncher'>
Set some path information.
%%px
import sys, os, shutil
basedir = ''
if "__file__" in globals(): basedir = os.path.dirname(__file__)
sys.path.insert(0, os.path.join(basedir, os.path.pardir, os.path.pardir, os.path.pardir, 'python'))
Loading everything we need from sz_problem and also set our default plotting and output preferences.
%%px
import fenics_sz.utils
from fenics_sz.sz_problems.sz_params import allsz_params
from fenics_sz.sz_problems.sz_slab import create_slab, plot_slab
from fenics_sz.sz_problems.sz_geometry import create_sz_geometry
from fenics_sz.sz_problems.sz_steady_dislcreep import SteadyDislSubductionProblem
import numpy as np
import dolfinx as df
import pyvista as pv
import pathlib
output_folder = pathlib.Path(os.path.join(basedir, "output"))
output_folder.mkdir(exist_ok=True, parents=True)
import hashlib
import zipfile
import requests
from mpi4py import MPI
comm = MPI.COMM_WORLD
my_rank = comm.rank
Parameters#
We first select the name and resolution scale, resscale of the model.
Resolution
By default the resolution is low to allow for a quick runtime and smaller website size. If sufficient computational resources are available set a lower resscale to get higher resolutions and results with sufficient accuracy.
%%px
name = "11_C_Peru_Gap"
resscale = 3.0
Then load the remaining parameters from the global suite.
%%px
szdict = allsz_params[name]
if my_rank == 0:
print("{}:".format(name))
print("{:<20} {:<10}".format('Key','Value'))
print("-"*85)
for k, v in allsz_params[name].items():
if v is not None and k not in ['z0', 'z15']: print("{:<20} {}".format(k, v))
[stdout:0] 11_C_Peru_Gap:
Key Value
-------------------------------------------------------------------------------------
coast_distance 150
extra_width 20
lc_depth 55
io_depth 186
uc_depth 15
dirname 11_C_Peru_Gap
As 40.0
qs 0.07999999999999999
A 33.9
sztype continental
Vs 66.7
xs [0, 42.9, 178.0, 233.0, 269.2, 278.1, 343.0, 459.0, 1000.0]
ys [-6, -15.0, -55.0, -70.0, -80.0, -82.5, -100.0, -125.0, -240.0]
Any of these can be modified in the dictionary.
Several additional parameters can be modified, for details see the documentation for the SteadyDislSubductionProblem class.
%%px
if my_rank == 0: help(SteadyDislSubductionProblem.__init__)
[stdout:0] Help on function __init__ in module fenics_sz.sz_problems.sz_base:
__init__(self, geom, **kwargs)
Initialize a BaseSubductionProblem.
Arguments:
* geom - an instance of a subduction zone geometry
Keyword Arguments:
required:
* A - age of subducting slab (in Myr) [required]
* Vs - incoming slab speed (in mm/yr) [required]
* sztype - type of subduction zone (either 'continental' or 'oceanic') [required]
* Ac - age of the overriding plate (in Myr) [required if sztype is 'oceanic']
* As - age of subduction (in Myr) [required if sztype is 'oceanic']
* qs - surface heat flux (in W/m^2) [required if sztype is 'continental']
optional:
* Ts - surface temperature (deg C, corresponds to non-dim)
* Tm - mantle temperature (deg C, corresponds to non-dim)
* kc - crustal thermal conductivity (non-dim) [only has an effect if sztype is 'continental']
* km - mantle thermal conductivity (non-dim)
* rhoc - crustal density (non-dim) [only has an effect if sztype is 'continental']
* rhom - mantle density (non-dim)
* cp - isobaric heat capacity (non-dim)
* H1 - upper crustal volumetric heat production (non-dim) [only has an effect if sztype is 'continental']
* H2 - lower crustal volumetric heat production (non-dim) [only has an effect if sztype is 'continental']
optional (dislocation creep rheology):
* etamax - maximum viscosity (Pas) [only relevant for dislocation creep rheologies]
* nsigma - stress viscosity power law exponents (non-dim) [only relevant for dislocation creep rheologies]
* Aeta - pre-exponential viscosity constant (Pa s^(1/n)) [only relevant for dislocation creep rheologies]
* E - viscosity activation energy (J/mol) [only relevant for dislocation creep rheologies]
Setup#
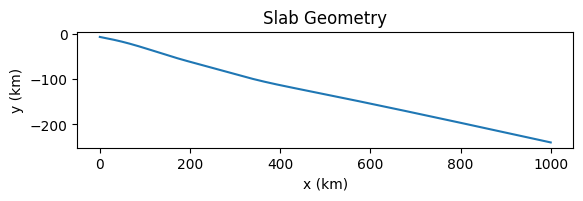
Setup a slab.
%%px
slab = create_slab(szdict['xs'], szdict['ys'], resscale, szdict['lc_depth'])
if my_rank == 0: _ = plot_slab(slab)
[output:0]
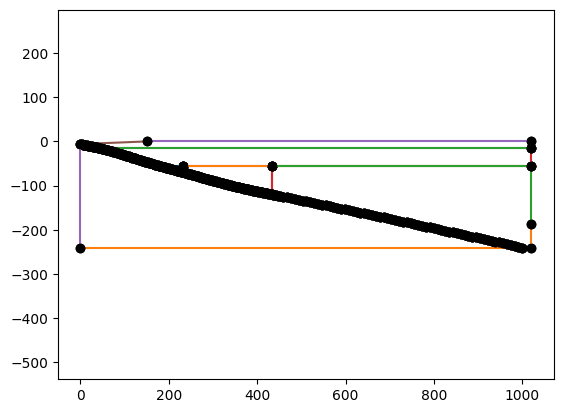
Create the subduction zome geometry around the slab.
%%px
geom = create_sz_geometry(slab, resscale, szdict['sztype'], szdict['io_depth'], szdict['extra_width'],
szdict['coast_distance'], szdict['lc_depth'], szdict['uc_depth'])
if my_rank == 0: _ = geom.plot()
[output:0]
Finally, declare the SubductionZone problem class using the dictionary of parameters.
%%px
sz = SteadyDislSubductionProblem(geom, **szdict)
Solve#
Solve using a dislocation creep rheology and assuming a steady state.
%%px
sz.solve()
[stdout:0] Iteration Residual Relative Residual
------------------------------------------
0 2205.56 1
1 319.674 0.14494
2 119.544 0.0542013
3 50.1843 0.0227536
4 25.324 0.0114819
5 15.2946 0.00693459
6 10.1551 0.00460434
7 7.0191 0.00318246
8 4.97983 0.00225786
9 3.60961 0.0016366
10 2.66477 0.00120821
11 1.99407 0.000904114
12 1.50633 0.000682972
13 1.14486 0.000519078
14 0.873142 0.000395883
15 0.666826 0.000302339
16 0.509045 0.000230801
17 0.387794 0.000175826
18 0.294332 0.00013345
19 0.222201 0.000100746
20 0.166557 7.55168e-05
21 0.123703 5.60868e-05
22 0.0908004 4.11689e-05
23 0.0656588 2.97697e-05
24 0.046574 2.11167e-05
25 0.0322314 1.46137e-05
26 0.0216185 9.80182e-06
27 0.0139851 6.34082e-06
28 0.00884335 4.00957e-06
Plot#
Plot the solution.
%%px
plotter = pv.Plotter()
fenics_sz.utils.plot.plot_scalar(sz.T_i, plotter=plotter, scale=sz.T0, gather=True, cmap='coolwarm', scalar_bar_args={'title': 'Temperature (deg C)', 'bold':True})
fenics_sz.utils.plot.plot_vector_glyphs(sz.vw_i, plotter=plotter, gather=True, factor=0.1, color='k', scale=fenics_sz.utils.mps_to_mmpyr(sz.v0))
fenics_sz.utils.plot.plot_vector_glyphs(sz.vs_i, plotter=plotter, gather=True, factor=0.1, color='k', scale=fenics_sz.utils.mps_to_mmpyr(sz.v0))
geom.pyvistaplot(plotter=plotter, color='green', width=2)
cdpt = slab.findpoint('Slab::FullCouplingDepth')
fenics_sz.utils.plot.plot_points([[cdpt.x, cdpt.y, 0.0]], plotter=plotter, render_points_as_spheres=True, point_size=10.0, color='green')
if my_rank == 0:
fenics_sz.utils.plot.plot_show(plotter)
fenics_sz.utils.plot.plot_save(plotter, output_folder / "{}_ss_solution_resscale_{:.2f}.png".format(name, resscale))
[stderr:1] 2026-05-08 22:28:29.654 ( 22.161s) [ 7F8F669EB140]vtkXOpenGLRenderWindow.:1416 WARN| bad X server connection. DISPLAY=:99
[stderr:0] 2026-05-08 22:28:29.651 ( 22.164s) [ 7FCF9E436140]vtkXOpenGLRenderWindow.:1416 WARN| bad X server connection. DISPLAY=:99
[output:0]

Save it to disk so that it can be examined with other visualization software (e.g. Paraview).
%%px
filename = output_folder / "{}_ss_solution_resscale_{:.2f}.bp".format(name, resscale)
with df.io.VTXWriter(sz.mesh.comm, filename, [sz.T_i, sz.vs_i, sz.vw_i]) as vtx:
vtx.write(0.0)
# zip the .bp folder so that it can be downloaded from jupyter lab
if my_rank == 0: shutil.make_archive(str(filename), 'zip', root_dir=str(filename.parent), base_dir=str(filename.name))
Comparison#
Compare to the published result from Wilson & van Keken, PEPS, 2023 (II) and van Keken & Wilson, PEPS, 2023 (III). The original models used in these papers are also available as open-source repositories on github and zenodo.
First download the minimal necessary data from zenodo and check it is the right version.
%%px
zipfilename = pathlib.Path(os.path.join(basedir, os.path.pardir, os.path.pardir, os.path.pardir, "data", "vankeken_wilson_peps_2023_TF_lowres_minimal.zip"))
# only one process should download the data
if my_rank == 0:
if not zipfilename.is_file():
zipfileurl = 'https://zenodo.org/records/13234021/files/vankeken_wilson_peps_2023_TF_lowres_minimal.zip'
r = requests.get(zipfileurl, allow_redirects=True)
open(zipfilename, 'wb').write(r.content)
# wait until rank 0 has downloaded the data
comm.barrier()
assert hashlib.md5(open(zipfilename, 'rb').read()).hexdigest() == 'a8eca6220f9bee091e41a680d502fe0d'
%%px
tffilename = os.path.join('vankeken_wilson_peps_2023_TF_lowres_minimal', 'sz_suite_ss', szdict['dirname']+'_minres_2.00.vtu')
tffilepath = os.path.join(basedir, os.path.pardir, os.path.pardir, os.path.pardir, 'data')
# one process should extract the file
if my_rank == 0:
with zipfile.ZipFile(zipfilename, 'r') as z:
z.extract(tffilename, path=tffilepath)
# other processes should wait
comm.barrier()
%%px
fxgrid = fenics_sz.utils.plot.grids_scalar(sz.T_i)[0]
tfgrid = pv.get_reader(os.path.join(tffilepath, tffilename)).read()
diffgrid = fenics_sz.utils.plot.pv_diff(fxgrid, tfgrid, field_name_map={'T':'Temperature::PotentialTemperature'}, pass_point_data=True)
%%px
# first gather the data onto rank 0
diffgrid_g = fenics_sz.utils.plot.pyvista_grids(diffgrid.cells, diffgrid.celltypes, diffgrid.points, comm, gather=True)
T_g = comm.gather(diffgrid.point_data['T'], root=0)
for r, grid in enumerate(diffgrid_g):
grid.point_data['T'] = T_g[r]
grid.set_active_scalars('T')
grid.clean(tolerance=1.e-2)
diffgrid_g
# then plot it
plotter_diff = pv.Plotter()
clim = None
for grid in diffgrid_g:
plotter_diff.add_mesh(grid, cmap='coolwarm', clim=clim, scalar_bar_args={'title': 'Temperature Difference (deg C)', 'bold':True})
geom.pyvistaplot(plotter=plotter_diff, color='green', width=2)
cdpt = slab.findpoint('Slab::FullCouplingDepth')
#fenics_sz.utils.plot.plot_points([[cdpt.x, cdpt.y, 0.0]], plotter=plotter_diff, render_points_as_spheres=True, point_size=10.0, color='green')
plotter_diff.enable_parallel_projection()
plotter_diff.view_xy()
if my_rank == 0: plotter_diff.show()
[output:0]
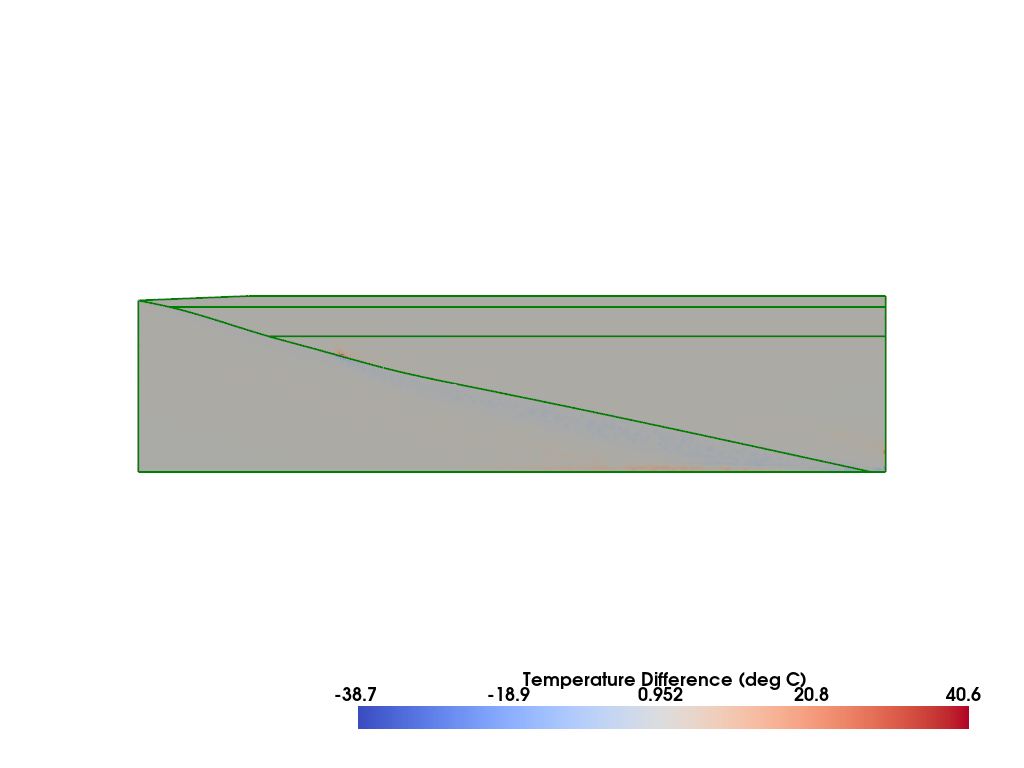
%%px
integrated_data = diffgrid.integrate_data()
totalarea = comm.allreduce(integrated_data['Area'][0], op=MPI.SUM)
error = comm.allreduce(integrated_data['T'][0], op=MPI.SUM)/totalarea
if my_rank == 0: print("Average error = {}".format(error,))
assert np.abs(error) < 5
[stdout:0] Average error = 0.2521985735509522
Shutdown#
Shutdown the ipyparallel cluster engine. Running the cell below will prevent earlier cells (with %%px as the first line) from being re-run.
rc.shutdown()